
分布式事务Seata
一、背景
Simple Extensible Autonomous Transaction Architecture,是一套一站式分布式事务解决方案
-
Seata用于解决分布式事务
-
Seata非常适合解决微服务分布式事务【dubbo、SpringCloud....】
-
Seata性能高
-
Seata使用简单
二、Seata事务模式
Seata 会有 4 种分布式事务解决方案,分别是 AT 模式、TCC 模式、Saga 模式和 XA 模式。
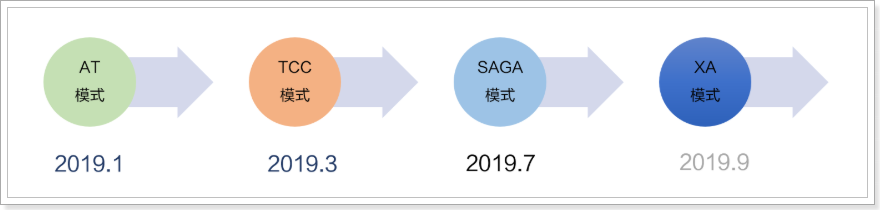
1、AT模式
2019年 1 月份,Seata 开源了 AT 模式。AT 模式是一种无侵入的分布式事务解决方案。可以看做是对TCC模型的一种优化,解决了TCC模式中的代码侵入、编码复杂等问题。
在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
可以参考Seata的官方文档。
先来看一张流程图:
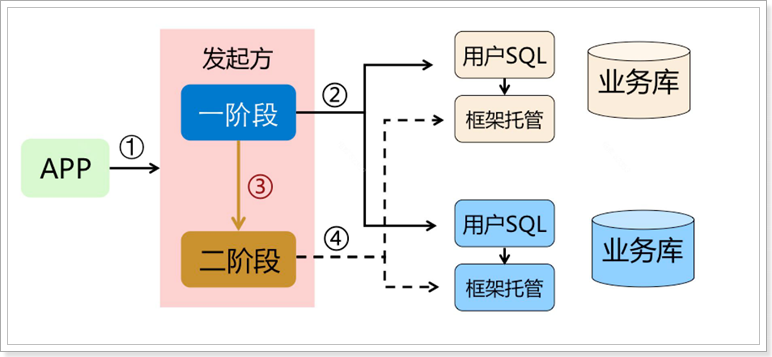
有没有感觉跟TCC的执行很像,都是分两个阶段:
- 一阶段:执行本地事务,并返回执行结果
- 二阶段:根据一阶段的结果,判断二阶段做法:提交或回滚
但AT模式底层做的事情可完全不同,而且第二阶段根本不需要我们编写,全部有Seata自己实现了。也就是说:我们写的代码与本地事务时代码一样,无需手动处理分布式事务。
那么,AT模式如何实现无代码侵入,如何帮我们自动实现二阶段代码的呢?
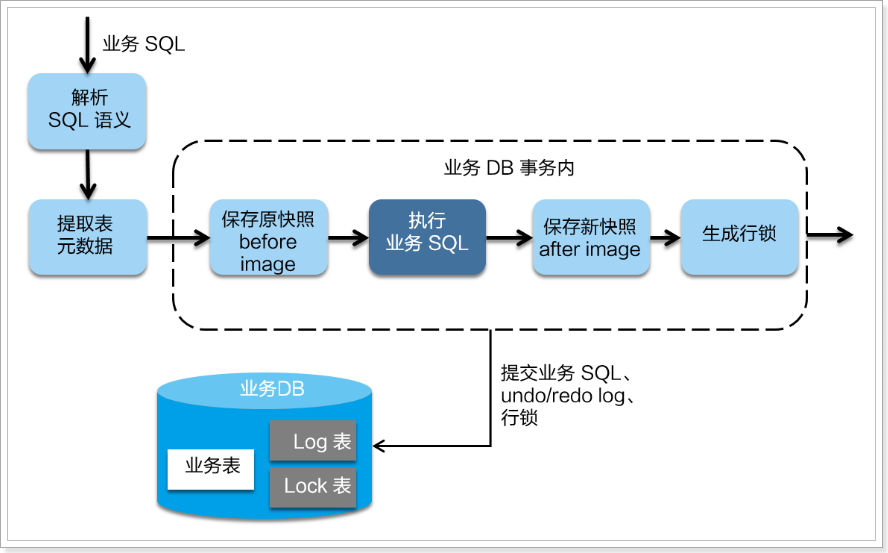
一阶段
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后获取全局行锁,提交事务。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
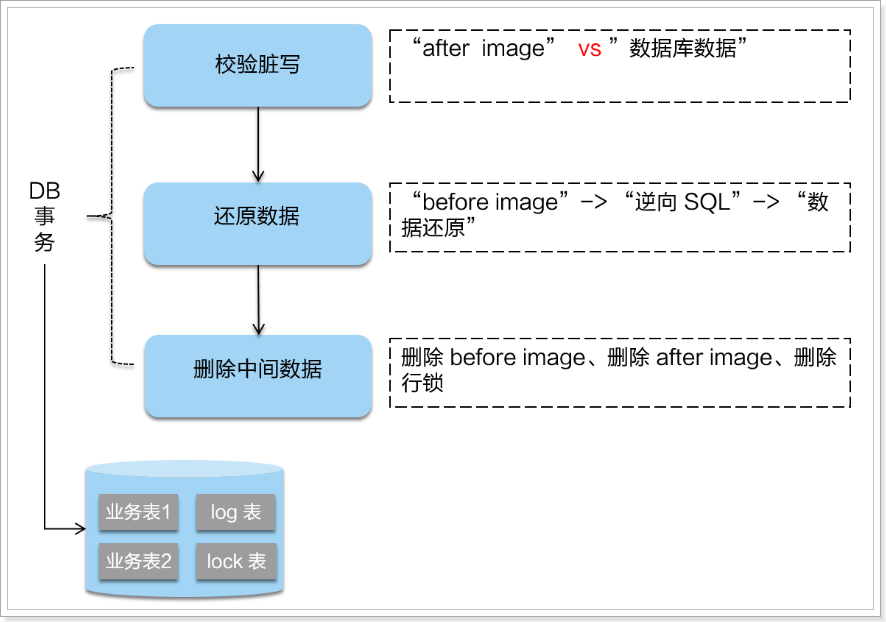
二阶段提交
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
不过因为有全局锁机制,所以可以降低出现脏写的概率。
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
2、详细架构和流程
Seata中的几个基本概念:
-
TC(Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚(TM之间的协调者)。
-
TM(Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
-
RM(Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
我们看下面的一个架构图
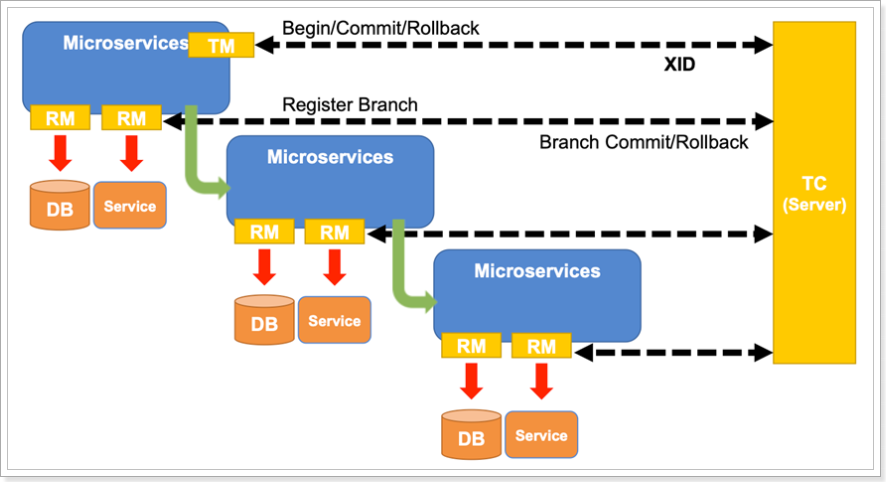
- TM:业务模块中全局事务的开启者
- 向TC开启一个全局事务
- 调用其它微服务
- RM:业务模块执行者中,包含RM部分,负责向TC汇报事务执行状态
- 执行本地事务
- 向TC注册分支事务,并提交本地事务执行结果
- TM:结束对微服务的调用,通知TC,全局事务执行完毕,事务一阶段结束
- TC:汇总各个分支事务执行结果,决定分布式事务是提交还是回滚;
- TC 通知所有 RM 提交/回滚 资源,事务二阶段结束。
一阶段:
- TM开启全局事务,并向TC声明全局事务,包括全局事务XID信息
- TM所在服务调用其它微服务
- 微服务,主要有RM来执行
- 查询
before_image - 执行本地事务
- 查询
after_image - 生成
undo_log并写入数据库 - 向TC注册分支事务,告知事务执行结果
- 获取全局锁(阻止其它全局事务并发修改当前数据)
- 释放本地锁(不影响其它业务对数据的操作)
- 查询
- 待所有业务执行完毕,事务发起者(TM)会尝试向TC提交全局事务
二阶段:
- TC统计分支事务执行情况,根据结果判断下一步行为
- 分支都成功:通知分支事务,提交事务
- 有分支执行失败:通知执行成功的分支事务,回滚数据
- 分支事务的RM
- 提交事务:直接清空
before_image和after_image信息,释放全局锁 - 回滚事务:
- 校验after_image,判断是否有脏写
- 如果没有脏写,回滚数据到
before_image,清除before_image和after_image - 如果有脏写,请求人工介入
- 提交事务:直接清空
工作机制参考Seata的官方文档:https://seata.io/zh-cn/docs/overview/what-is-seata.html
3、优缺点
优点:
- 与2PC相比:每个分支事务都是独立提交,不互相等待,减少了资源锁定和阻塞时间
- 与TCC相比:二阶段的执行操作全部自动化生成,无代码侵入,开发成本低
缺点:
- 与TCC相比,需要动态生成二阶段的反向补偿操作,执行性能略低于TCC
- 可能会出现数据脏读现象
三、Seata Server端环境准备
1、seata配置文件
- registry.conf 对应配置如下:
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
# 指定注册中心类型,这里使用 file 类型
type = "file"
# 各种注册中心的配置
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
username = ""
password = ""
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = 0
password = ""
cluster = "default"
timeout = 0
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
# 配置文件方式,可以支持 file、nacos 、apollo、zk、consul、etcd3
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
appId = "seata-server"
apolloMeta = "http://192.168.1.204:8801"
namespace = "application"
}
zk {
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
etcd3 {
serverAddr = "http://localhost:2379"
}
# 配置文件的名称
file {
name = "file.conf"
}
}
这个文件主要配置两个内容:
- 注册中心的类型及地址,本例我们选择file做注册中心
- 配置中心的类型及地址,本例我们选择本地文件做配置,就是当前目录的
file.conf文件
file.conf 配置文件:
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
}
service {
# 修改vgroup_mapping
#vgroup->rgroup【注意这里的分组名为heima_leadnews_tx_group】
vgroup_mapping.heima_leadnews_tx_group = "default"
#only support single node
#修改连接TC Seata server 端地址【注意修改这里seata服务端的地址】
default.grouplist = "192.168.200.130:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
}
## transaction log store, only used in seata-server
store {
## store mode: file、db、redis
mode = "file"
## file store property
file {
## store location dir
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
maxBranchSessionSize = 16384
# globe session size , if exceeded throws exceptions
maxGlobalSessionSize = 512
# file buffer size , if exceeded allocate new buffer
fileWriteBufferCacheSize = 16384
# when recover batch read size
sessionReloadReadSize = 100
# async, sync
flushDiskMode = async
}
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/restkeeper_seata"
user = "root"
password = "root"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
## redis store property
redis {
host = "127.0.0.1"
port = "6379"
password = ""
database = "0"
minConn = 1
maxConn = 10
queryLimit = 100
}
}
2、Seata Server启动
如果使用docker安装并且使用的是默认的 file 模式只需要运行docker命令即可:
docker run --name seata --restart=always -p 8091:8091 -e SEATA_IP=192.168.200.130 -e SEATA_PORT=8091 -id seataio/seata-server:1.3.0
四、项目继承Seata
1、初始化准备
分别在要用到分布式事务的服务的两个库中都创建undo_log表
注意此处seata版本是0.7.0+ 增加字段 context
CREATE TABLE `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT(20) NOT NULL,
`xid` VARCHAR(100) NOT NULL,
`context` VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
- 导入依赖包
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>1.3.0</version>
<exclusions>
<exclusion>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
</dependencies>
2、创建代理数据源
/**
* 数据源代理配置类,取代数据源的自动配置类,由Seata统一管理数据源
*/
@Configuration
@EnableConfigurationProperties({MybatisPlusProperties.class})
public class DataSourcesProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
return new DruidDataSource();
}
//创建代理数据源
@Primary//@Primary标识必须配置在代码数据源上,否则本地事务失效
@Bean
public DataSourceProxy dataSourceProxy(DataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
private MybatisPlusProperties properties;
public DataSourcesProxyConfig(MybatisPlusProperties properties) {
this.properties = properties;
}
//替换SqlSessionFactory的DataSource
@Bean
public MybatisSqlSessionFactoryBean sqlSessionFactory(DataSourceProxy dataSourceProxy) throws Exception {
// 这里必须用 MybatisSqlSessionFactoryBean 代替了 SqlSessionFactoryBean,否则 MyBatisPlus 不会生效
MybatisSqlSessionFactoryBean mybatisSqlSessionFactoryBean = new MybatisSqlSessionFactoryBean();
mybatisSqlSessionFactoryBean.setDataSource(dataSourceProxy);
mybatisSqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
mybatisSqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath*:/mapper/*.xml"));
MybatisConfiguration configuration = this.properties.getConfiguration();
if(configuration == null){
configuration = new MybatisConfiguration();
}
mybatisSqlSessionFactoryBean.setConfiguration(configuration);
// 设置分页插件****
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
List<ISqlParser> sqlParserList = new ArrayList<ISqlParser>();
// 攻击 SQL 阻断解析器、加入解析链
sqlParserList.add(new BlockAttackSqlParser());
paginationInterceptor.setSqlParserList(sqlParserList);
Interceptor[] plugins = { paginationInterceptor };
mybatisSqlSessionFactoryBean.setPlugins( plugins );
return mybatisSqlSessionFactoryBean;
}
}
3、指定事务分组
spring:
cloud:
alibaba:
seata:
tx-service-group: leafl_tx_group
autoconfigure:
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
- 配置 tx 事务分组名称需要和 leafl_tx_group 配置文件的分组保持一致
- 排除SpringBoot的 数据库的自动化配置类
4、使用
- 注意,此时@Mapper注解不起作用了,必须使用@MapperScan注解统一扫描Mapper,在用到的服务的启动类添加扫描:
@MapperScan(basePackages = "com.leaflei.mapper")
- @GlobalTransactional注解

- 注意事项
- 如果被调用方存在异步任务,那么不光要在事务发起方加注解。被调用方也要加注解!!!

