
Kafka分区和消费
AI-摘要
Tianli GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
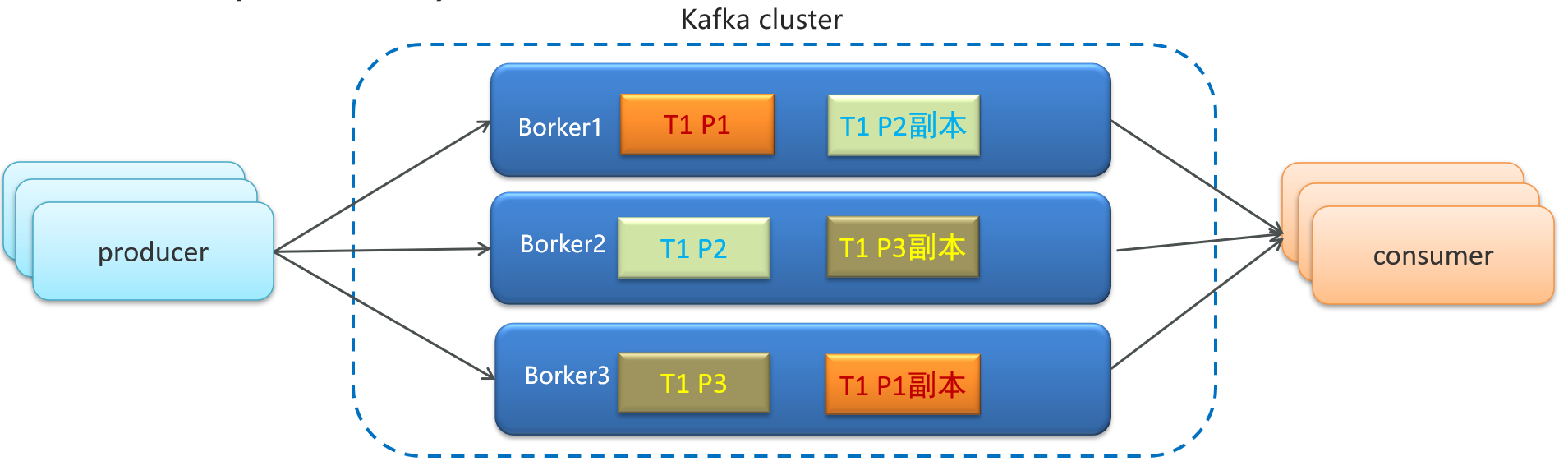
一、分区机制
-
同一个Topic包含不同的Partition(分区)存储在不同机器
-
一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先进先出的顺序读取
-
Partition分区的好处是可以并行读和写,保证kafka高吞吐、高性能、高可用
-
每个Partition针对每一个消费组设计了独立的偏移量(offset)
在kafka容器内/opt/kafka_2.12-2.3.1/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,默认是1
二、不同消费组可以重复消费
- 分区针对消费组具有独立的偏移(offset)设计
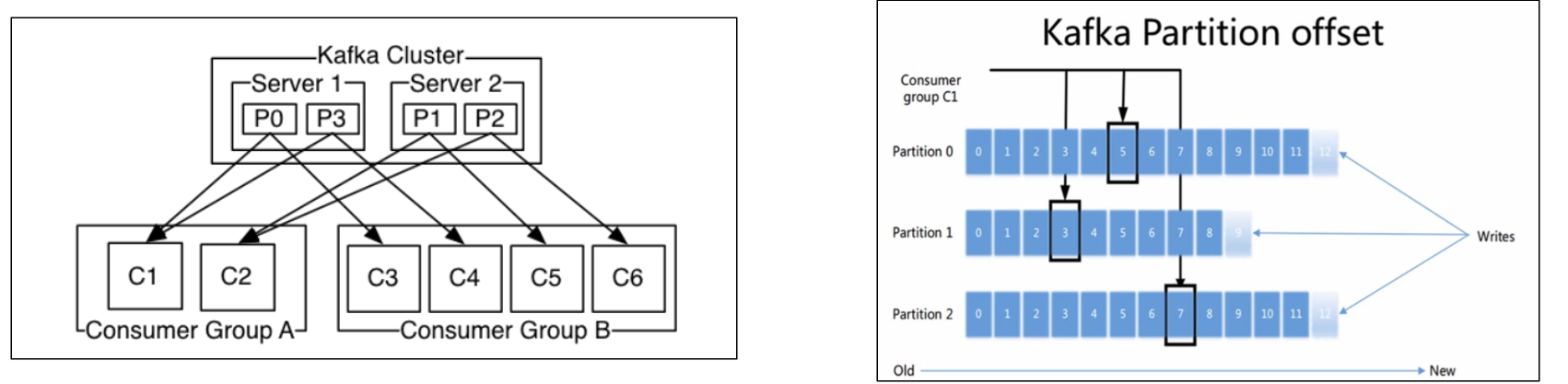
- offset: 任何发布到partition的消息会被追加到log日志文件尾部( 由partition的leader记录,并由partition的follower同步),每条消息在文件中的位置就被称为offset(偏移量),offset是一个long型数字,是按照1自增的,它唯一标记一条消息。消费者通过(offset、partition、topic)跟踪记录。
可在配置文件server.properties配置log.dirs指定log日志文件目录 topic__consumer_offsets: 消费者组的位移提交到自带的topic__consumer_offsets里面,当有消费者第一次消费kafka数据时就会自动创建,它的副本数不受集群配置的topic副本数限制,分区数默认50(可以配置),默认压缩策略为compact。 当 Consumer 重启后,自动读取topic__consumer_offsets中位移数据,从而在上次消费截止的地方继续消费
三、查看Kafka日志
1、查看消费日志
-
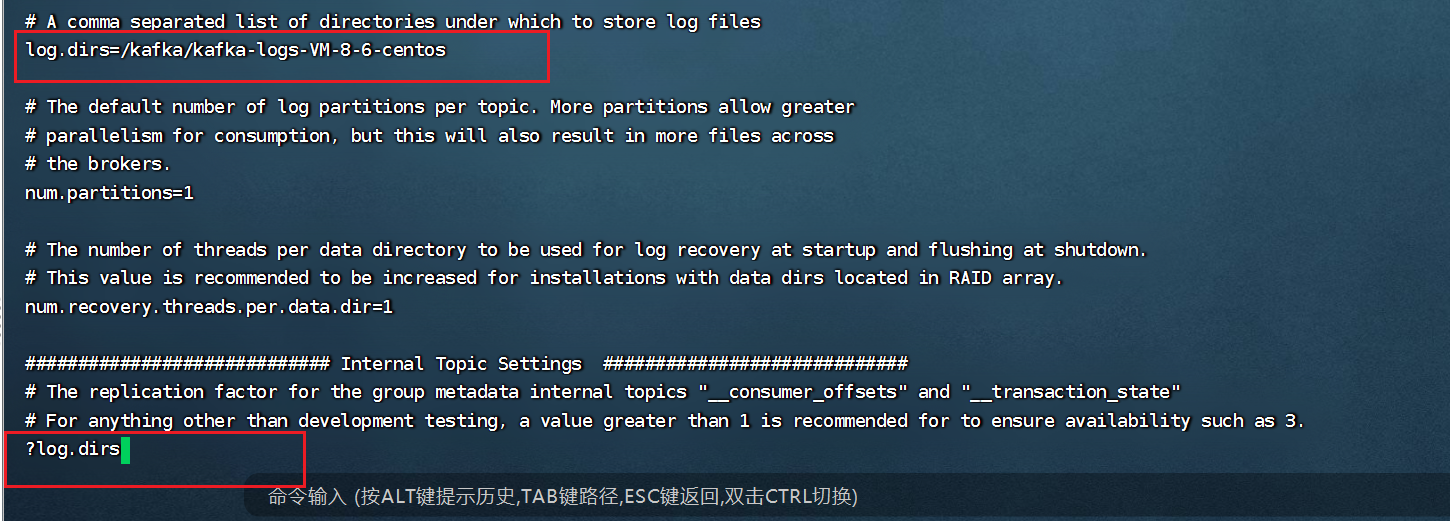
① 登录到kafka容器:docker exec –it kafka /bin/bash
-
Vi编辑配置文件:vi /opt/kafka_2.12-2.3.1/config/server.properties,在命令行输入
?log.dirs查找日志目录
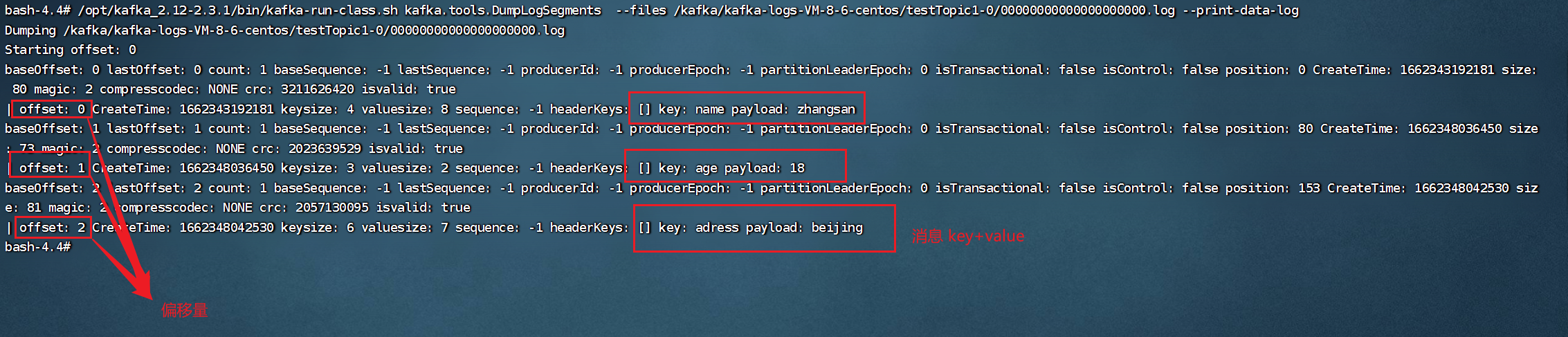
- ② 查看日志目录 ls /kafka/kafka-logs-VM-8-6-centos

- ③ 查看对应主题下的日志
/opt/kafka_2.12-2.3.1/bin/kafka-run-class.sh kafka.tools.DumpLogSegments \
--files /kafka/kafka-logs-VM-8-6-centos/testTopic1-0/00000000000000000000.log \
--print-data-log
# 注意 -- files 后面的路径/kafka/?/?/00000000000000000000.log ?的部分替换为自己的kafka路径
2、查看消费者偏移量日志
/opt/kafka_2.12-2.3.1/bin/kafka-consumer-groups.sh \
--bootstrap-server 101.42.152.102:9092 \
--describe --group kafka-demo-test
# 注意 --group 后面的参数为想要查询的指定消费者组群的名称

四、分区下的消费顺序问题
kafka能否保证顺序消费?
- 单机环境: 一个主题对应一个分区。单个分区内的消息写入有有序的,所以针对单个分区的消费是可以保证消费顺序的。
- 集群环境: 一个主题对应多个分区。例如连续进行如下5个操作,通过Kafka生产5条消息,由于Kafka是并行写消息并已追加的方式写入到多个不同分区,所以在整个主题范围内无法保证写的顺序,最后消费端数据消费也是无法保证顺序的。
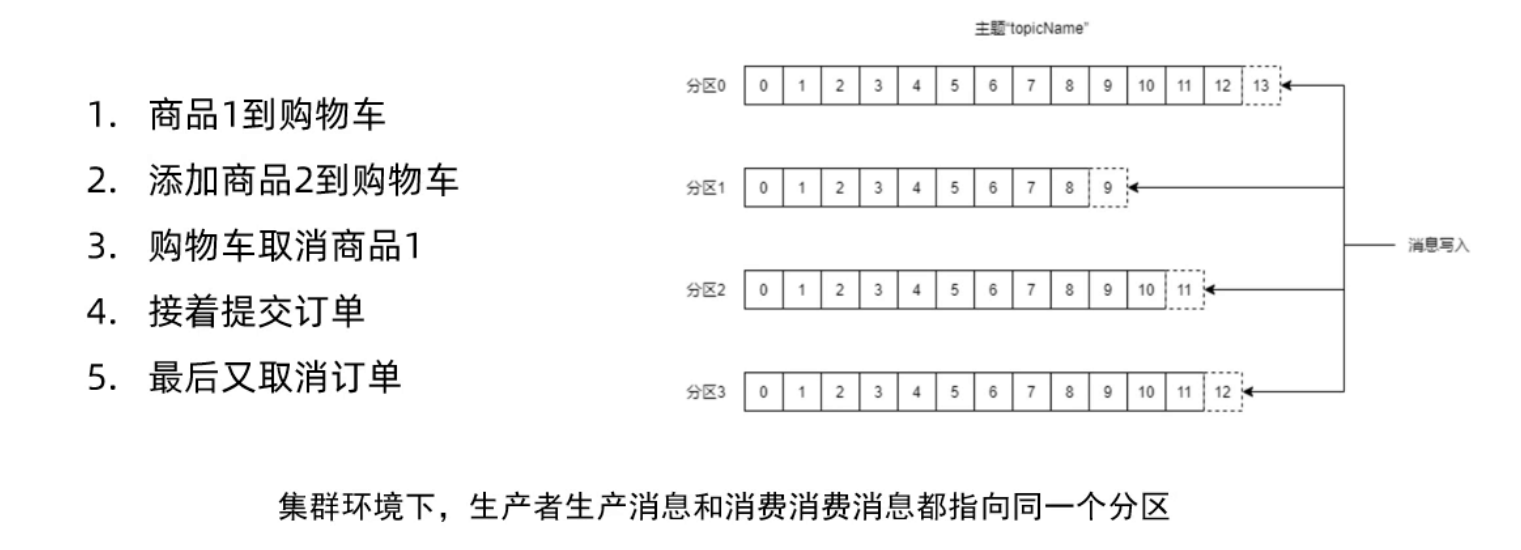
1、生产和消费时指定分区
注意:只有在生产key+value形式的消息的情况下,才有分区编号的概念
- 生产者
/**
* @Author :leaflei
* @Version: 1.0
* @Description :kafka生产者
*/
@RestController
public class ProducerController {
@Autowired
private KafkaTemplate kafkaTemplate;
/**
* 生产消息:value
*/
@GetMapping("/send2/{value}")
public String send2( @PathVariable("value") String value){
// 发送消息,value
kafkaTemplate.send("testTopic2", value);
return "ok";
}
/**
* 生产消息:key+value 同时指定分区编号
*/
@GetMapping("/send3/{key}/{value}")
public String send3(@PathVariable("key") String key, @PathVariable("value") String value){
// 发送消息,key+value , 同时指定分区编号0
kafkaTemplate.send("testTopic3",0,key, value);
return "ok";
}
}
- 消费者
- 如果一个监听器中存在多个消费者,有一个消费者指定了分区,其他消费者也必须指定分区,否则会触发重平衡
/**
* @Author :leaflei
* @Version: 1.0
* @Description :kafka消费者
*/
@Component
public class ConsumerListener {
/**
* 消费者监听 value
*
* @param consumerRecord 监听到的消息
*/
// @KafkaListener(topics = "testTopic2")
//因为testTopic3的生产者指定了分区,所以他的消费者也制定了分区,又因为一个监听器中如果有消费者指定了分区,其他消费者也要指定分区,否则会触发重平衡
@KafkaListener(topicPartitions = {@TopicPartition(topic = "testTopic2",partitions = {"0"})})
public void receiveMsg2(ConsumerRecord<String, String> consumerRecord) {
Optional<ConsumerRecord<String, String>> optional = Optional.ofNullable(consumerRecord);
optional.ifPresent(x -> System.out.println(x.value()));
}
/**
* 消费者监听 key+value ,同时指定分区编号
* @param consumerRecord 监听到的消息
*/
@KafkaListener(topicPartitions = {@TopicPartition(topic = "testTopic3",partitions = {"0"})})
public void receiveMsg3(ConsumerRecord<String, String> consumerRecord) {
Optional<ConsumerRecord<String, String>> optional = Optional.ofNullable(consumerRecord);
// 打印 key + value + 偏移量
optional.ifPresent(x -> System.out.println(x.key()+"==="+x.value()+"==="+x.offset()));
}
}
2、分区策略

本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 leaflei
阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果
最近发布